背景
数据库:Oracle 19c
1、STOCK 库存表
数据量:总数74w,查询条件DATA_AUTH,其中DATA_AUTH=100的23w,200的44w
200的比100的多很多,而且占总数的比例很大
索引:

2、ITEM 物料表
数据量:总数12w,其中100的3w,200的3w
100和200差不多
索引:

问题描述
查询语句:
查询100耗时:0.024s 结果 :23w条
查询200耗时:3s 结果:44w条
查询200的时候,速度非常慢
SELECT S.ID,I.ID FROM T_WMS_STOCK_INFO S
LEFT JOIN T_CO_ITEM I ON S.DATA_AUTH = S.DATA_AUTH AND S.ITEM_CODE = I.ITEM_CODE
WHERE S.DATA_AUTH ='100'排查过程
1、查看执行计划
200:

100:
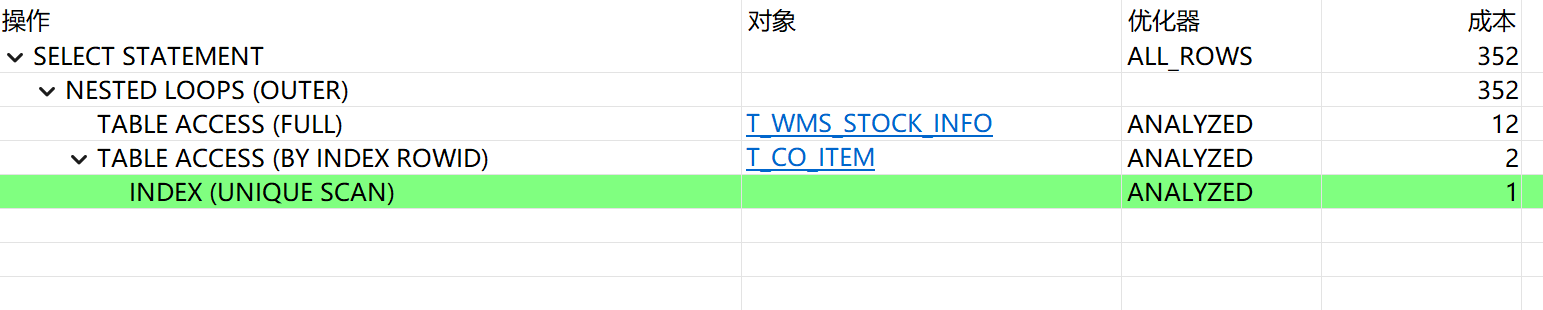
可以看到,查询200的sql,stock表使用了索引,评估成本更低,但是反而速度更慢。
而查询100的sql,stock表走了全表扫描,评估成本高非常多,但是实际速度更快。
而对item表的查询,100使用了range scan,200使用的是unique scan。
还有一个测试数据库,执行下试试:
发现使用了hash join关联,而不是nested loops,查询速度也非常快。不管是查询100还是200,都很快。

由于两边的索引和表结构,以及数据量都差不多,所以这里怀疑是优化器的问题。
直接查询stock表看下怎么用的索引:
SELECT *
FROM T_WMS_STOCK_INFO
WHERE DATA_AUTH = '8300' AND ITEM_CODE = '610C25Z00012';看到这里用的是05的索引,05是一个三个字段的复合索引,但是只有data_auth一个字段,而04是data_auth+item_code是两个字段,完美符合查询条件却没使用。

来测试环境试下:
正确使用!这里基本确定是优化器的问题了。

在正式环境,通过hint的方式指定索引查询。
SELECT /*+ INDEX(T_WMS_STOCK_INFO IX_T_WMS_STOCK_INFO_04) */ *
FROM T_WMS_STOCK_INFO
WHERE DATA_AUTH = '8300' AND ITEM_CODE = '610C25Z00012';索引正常使用,查询速度也没问题。

所以问题就在优化器没有正常工作。
解决方案
更新Oracle统计信息
call dbms_stats.gather_table_stats('用户名','T_WMS_STOCK_INFO');测试:
1、简单查询
已经正常使用索引

2、问题sql
使用了hash join 和测试环境一致,查询速度也恢复了
 完结撒花!
完结撒花!